Episode 1 Why distributed system
10/6/2023
Why distribute systems?
The Wrong reasons
- It’s fun
- My boss tells me to make it distributed systems/microservices
- make it distributed without experience because we worry of the future scalability.
The right reasons
- Scalability of course (balance the load across machines)
- Reduce latency for users around the globe, serve the request as fast as possible and this require us to make the server closer as we can to the user (better user experience), we still bounded by the light speed theoretically Latency Numbers Every Programmer Should Know.
- Availability, fault tolerance (under failure), Durability.
- Data residency under compliance for countries law (for example the country require the data of some sort to be physically in the country).
Node
the node which contain the compute (CPU) and state (memory, disk), it’s either a standalone machine or running process (a member of the the distributed systems).
Compute
The computing power which do the actual work The CPU.
State
Somewhere holds data memory, disk, or database.
Distributed systems
The process which we split the compute (CPU) or the state (memory, disk) or both (Node) into multiple machine and they are communicating asynchronously through unreliable communication channel (Can fail).
Stateless distributed system:
the state is offloaded. Which machine doesn’t hold the state, the state is persisted elsewhere and access it. for example web application running on many servers but they access the same database or database cluster.
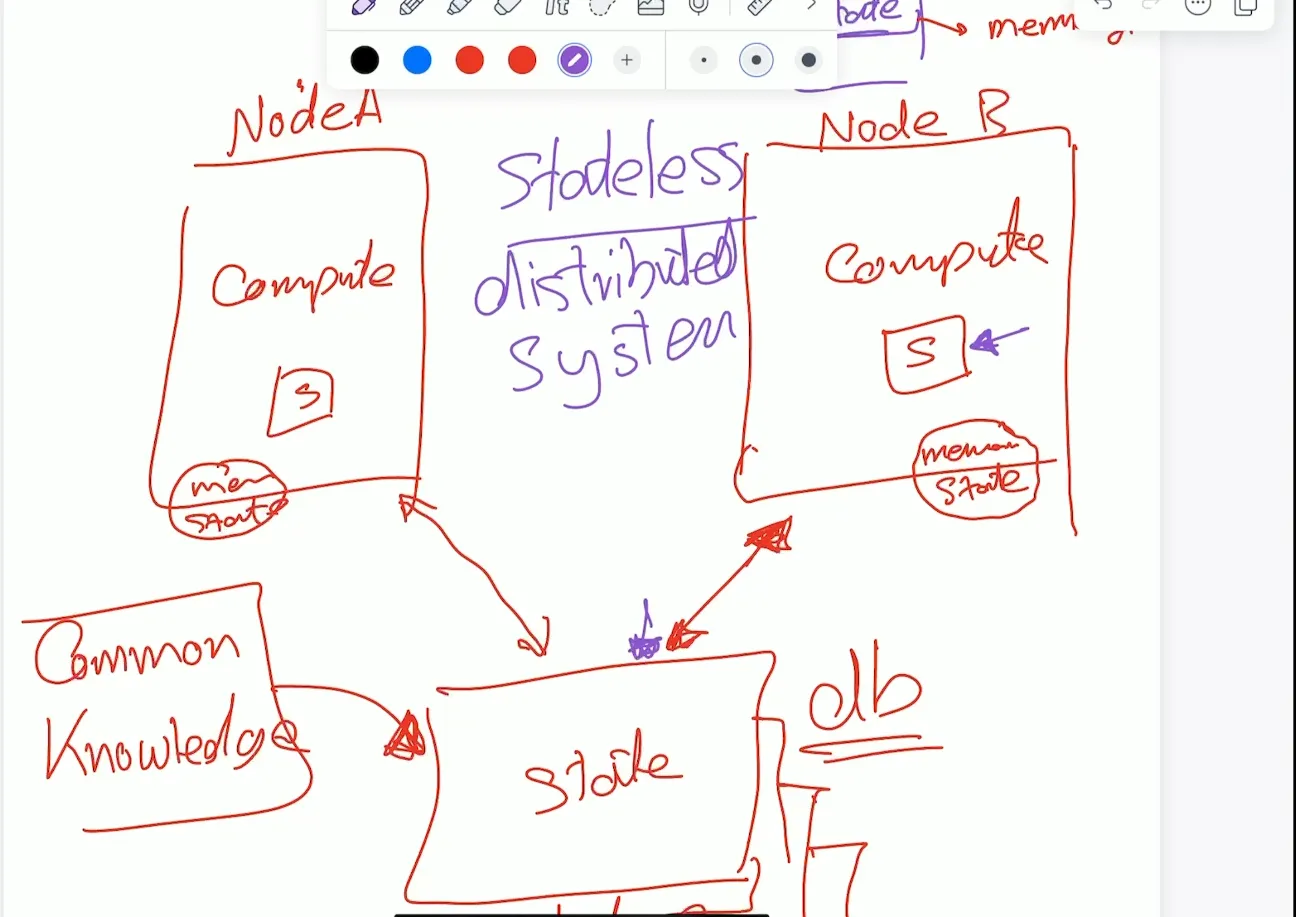
Stateful distributed system:
Every Node hold a state Which machine hold the state if it’s own. for example If we have Node A and Node B:
- if State A = State B then State A and State B is Replicas,
- if they are the same in any point of time. we call that Strong Consistency.
- if they are eventually will be the same we call that Eventual Constituency
- if the State = State A + State B we call that Sharding or Partitioning
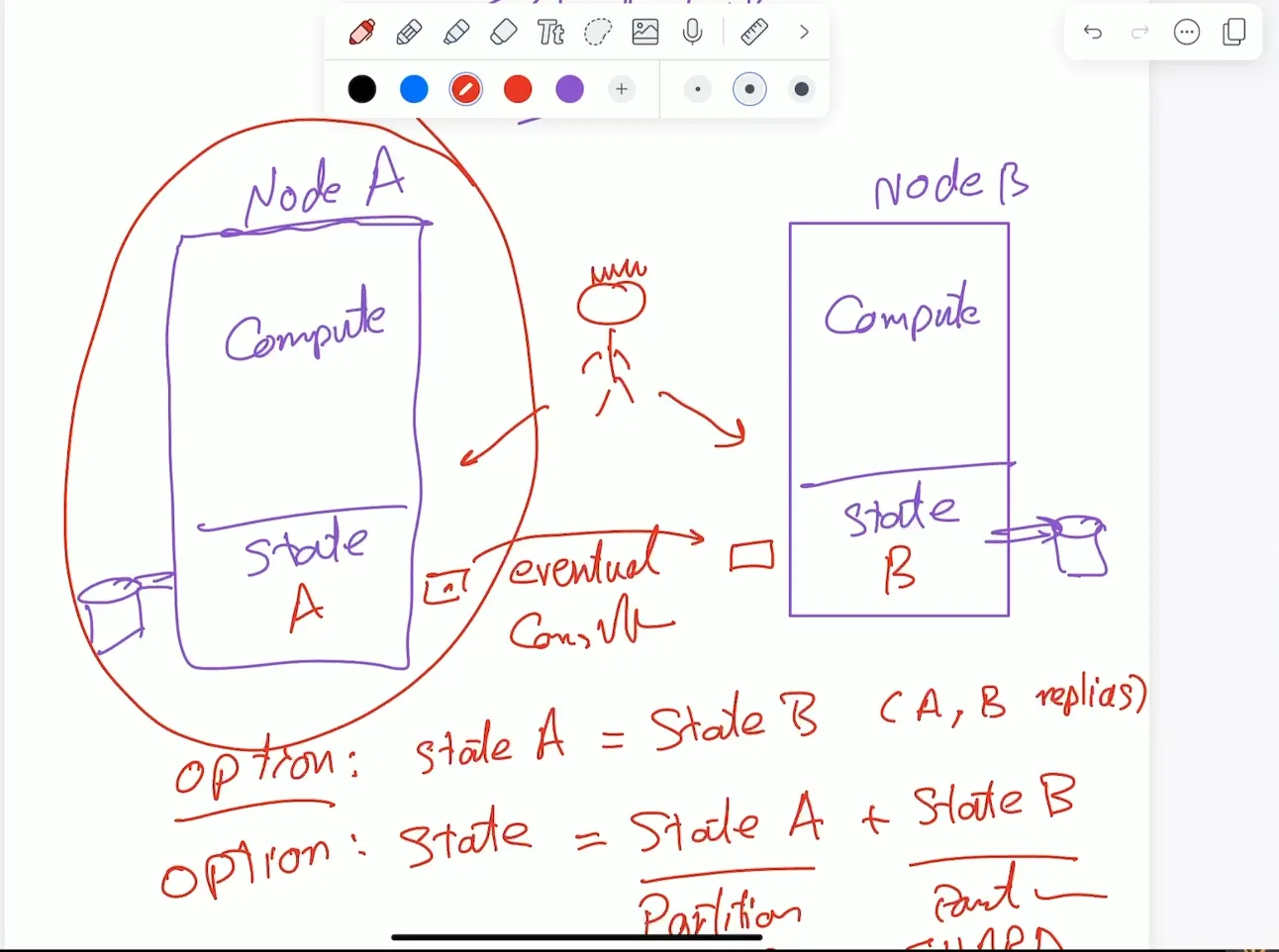 With this mechanism we trade of the availability because if one machine is down we do not have the whole state. to mitigate this problem how likely the company can pay for higher availability. like replicate the machine into whatever we want.
With this mechanism we trade of the availability because if one machine is down we do not have the whole state. to mitigate this problem how likely the company can pay for higher availability. like replicate the machine into whatever we want.
Fault tolerance
Node Failures
- Fail stop (hard failure): the node is either running or not stopped.
- Gray failure (byzantine failure): the node is running but it miss behaving. for example the node is very slow, or send wrong responses or corrupted result, or have old version of something. This is the hardest part of the distributed systems is to be resilient against the byzantine failure.
Network Failures
- Fail stop (hard failure).
- Gray failure (byzantine failure).
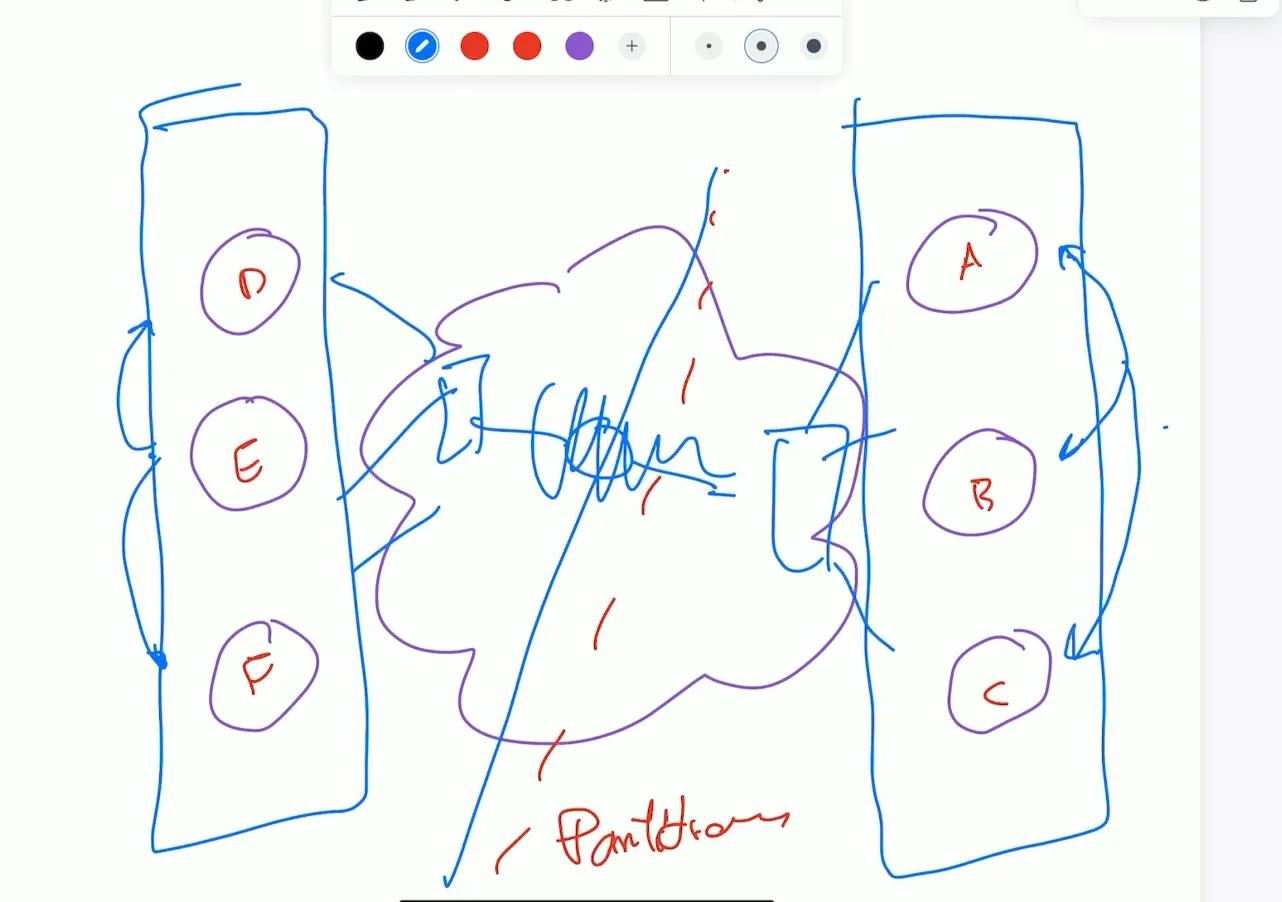
Network partitioning problem
Suppose we have 6 nodes the are connected through the network, the partitioning problem happened when there are subset of nodes separated from the others nodes and they think that they are the only nodes alive and same for the other nodes.
CAP theorem
CAP theorem C for Consistency, A for Availability, and P for Partitioning tolerance.
Do we have to be fault tolerant against all failures
Of course not and depend on the use case, the key here is what to trade for what Engineering is the Art of making tradeoffs and how to communicate that to business owner. It’s more important to solve how to recover from the failure not to be fault tolerant against (recoverable)
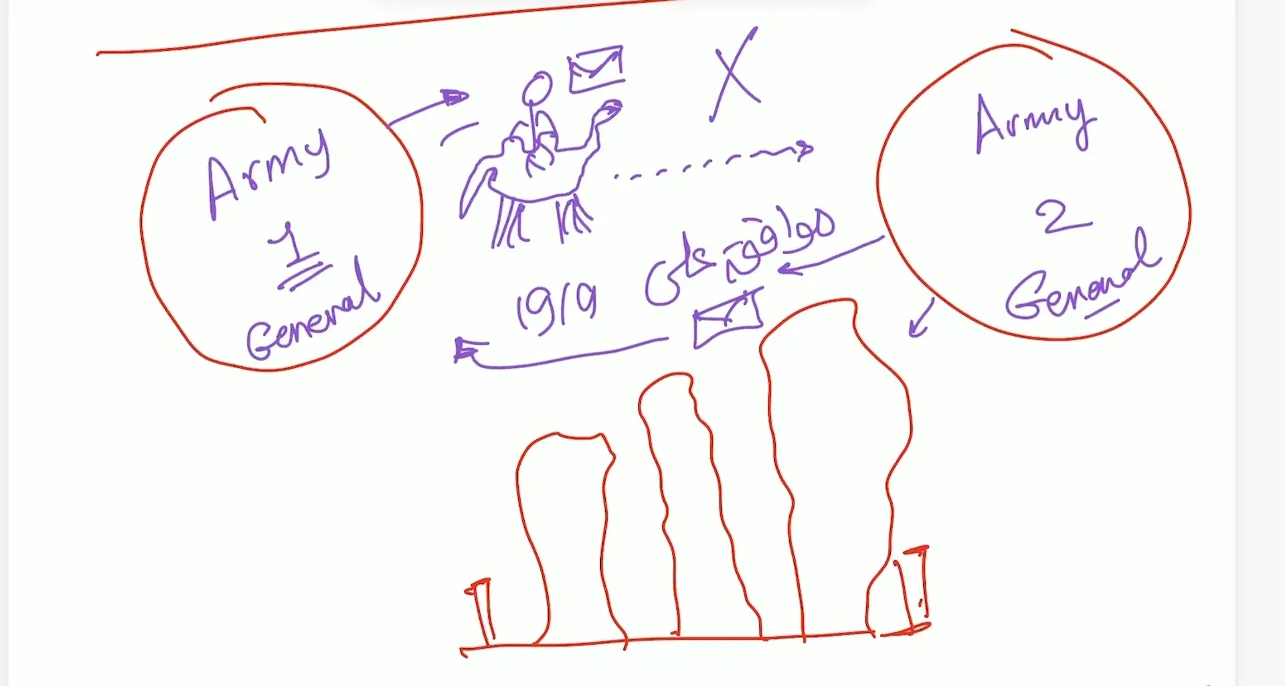
Two generals problem
Suppose we have two army (army 1 and army 2) they need to invade country but they must attack together in the same time to invade the country.
they must be communicating to agree on the time to invade, we suppose the messenger is authentic and the message will be received is authentic and true.
If we send the messenger from army 1 with certain time to invade and army 2 received the message and agree on the time he send another messenger to confirm the invade time.
The problem here from army 1 point he send the messenger and assume the army 2 received it and he will attack on the time or he wait the response from Army 2 to confirm but from Army 2 point he confirm the time and send the messenger but he didn’t know if army 1 received the confirmation or not, Do we make army 1 send another messenger to confirm the confirmation, we are stuck in a loop, it’s require send and received infinite number of messages to confirm the time, This type problem called Consensus (common knowledge). to reach the consensus we require infinite number of messages (assurance problem). No Solution for this problem for 100%.
Byzantine Generals problem
The same as the previous problem but the messages is will be received 100% we assure that the message will be received but the message maybe it’s corrupted or the messenger is disloyal or one of the army is actively send wrong information (gray failure the army or the node is running but actively send wrong messages or corrupted or compromised or the messenger late).
Consensus Problem
In distributed systems each node has state, All Node must agreed on One state (Consensus) in unreliable communication channels between the nodes. There are a class algorithms specialize in solving consensus problem for example Paxos, and Raft